Merging two data files
Intro
FYI: This post is going to be a pretty straight forward and applied one (also a bit of a rant).
For reasons that I don’t understand, when Digital Innovations (DI; now owned by ESO) added its ITDX module to Collector, they didn’t seem to take the time to carefully integrate those new fields into their existing data model. Instead, they seem to have just duct taped those new data elements on top of the existing system. As a result, you can’t access the ITDX elements from Report Writer—you have to use ITDX Report Writer to get those data.
So, what’s the big deal? Well, there are a few, but the biggest one for me is that it turns what could and should be a relatively simple process for users into a hassle—as highlighted with the following example.
Imagine you wanted to run a report looking at injury mechanism, initial ED vital signs, ED discharge disposition, and blood product utilization. The first step is to make the report with the injury mechanism, vital signs, and ED discharge disposition in Report Writer—easy enough. But now you also need to open and log in to the ITDX Report Writer to make a second report for the data on blood products. And you might want to make a query for each of those reports: one for the Report Writer report, for example, to only include blunt injuries and another for the ITDX version to only include patients who received blood products in the first four hours. Once you’ve built those reports and queries, you’re finally ready to run the reports. And now you have two data files that you need to merge together, so you (almost certainly) open them up in Excel and use formulas to join them together.
Admittedly, these aren’t big issues, but the cumulative result is a big time suck for a pretty basic report. Sadly, I can’t do much to help with most of the above process. However, I can help with the last part: merging the two reports.
The old way of merging two files
I made some fake but realistic data to show how much time can be spent on just trying to merge two data files together using the formulas in Excel. Here’s a recording of me going through this process.
As you can see, that took me nearly a minute to go through all the steps required to merge those two files: copy the data, add the new headers, write the formula (while looking at a cheat sheet), and copy it to the rest of the column. And that’s using the new XLOOKUP function, which is much more convenient than VLOOKUP, on a single column of data.
Imagine if I had to do this for all the TQIP process measures!
Now, admittedly, if I’m clever about how I write the formula, I can simply copy and paste the first column of XLOOKUPs into the remaining columns, but that’s still lot of (error prone) clicking around and typing. Plus, I would want to go back and replace the formulas with just the values via a ‘paste and keep values only’ so they don’t get messed up later, and I’d want to then delete the data in columns Q through V. I timed this process out too, and it took me another 53 seconds to do all of that. So realistically, it takes at least two minutes to fully merge even just these two small datasets. And I have to do this every single time I want ITDX data.
There has got to be a better way…
A better way
After a bit of digging, I found that there are some really helpful data manipulation tools embedded in the inner workings of Excel. The problem for most users is actually getting to and then understanding those tools. Thankfully, I’ve made that part easy for you. I created a macro-enabled Excel workbook that enables you merge data from two files with ease. You can download it here.
As you can see, that took me ~27 seconds to completely merge the files. Compare that to the 57 seconds it took me to merge one column using XLOOKUP. Assuming another 53 seconds to complete the XLOOKUP process, that makes my tool just over four times faster from start to finish—and it doesn’t require any error-prone typing of formulas.
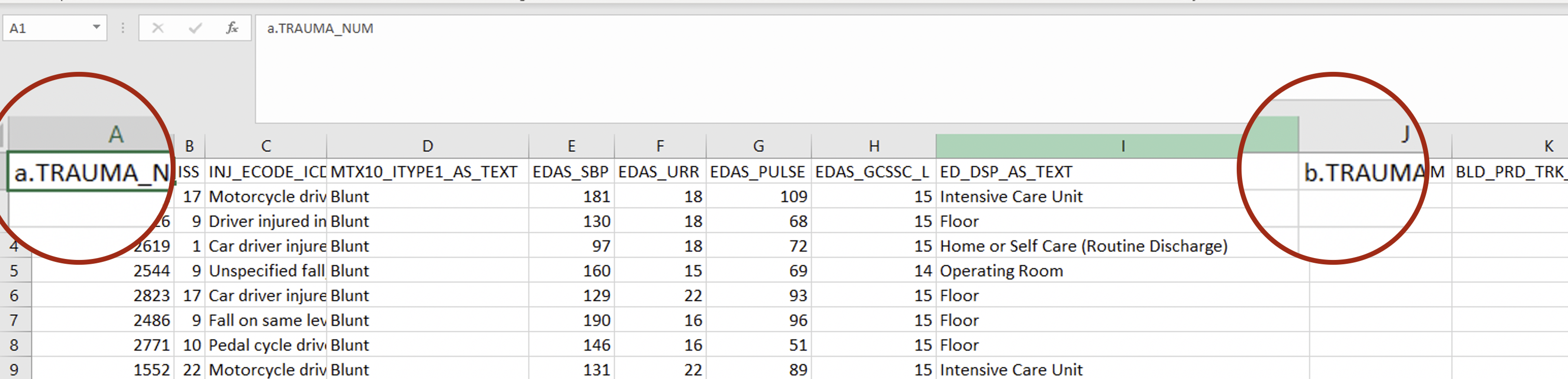
Now, one thing to note about this tool is that any columns that are
present in both files will have their names changed slightly. As you can
see below, in this case, TRAUMA_NUM from the first file is renamed to
a.TRAUMA_NUM and TRAUMA_NUM from the second file is renamed to
b.TRAUMA_NUM. This is because the underlying software needs the column
headings to be unique. Rather than simply assuming that it should get
rid of one column but keep the other, it simply renames them slightly.
The renaming will always follow the convention that columns from the
first file will have “a.” added to the front, and columns from the
second file will have “b.” added.
Conclusion
I made this merge tool after a meeting with my PI coordinator a few months back where she mentioned what a pain it was for her to merge the ITDX data in with the other registry data. I hadn’t realized what a pain it would be for people who don’t have access to stats software to do this rather common task—and it is a pain. After a few weeks of off-and-on work on this tool, I sent it to her to get her thoughts on it, and she loved it.
Admittedly, this tool doesn’t save users a ton of time (just a minute or two here and there), but my PI coordinator and I both felt like the process is vastly more pleasant—and that’s coming from a guy who loves data and coding. I really hope this merge tool can help other users of trauma registry data be more productive and avoid one of the hassles that DI’s ITDX module introduced. And even though I made this tool for this rather specific situation, you can use it for just about any circumstance where you have some variables in one file and other variables in another file.
I really do hope this tool will be helpful, but if you run into issues with it or have questions, send me an email or leave a comment below. I’d also love suggestions for future topics.
To see the code I used to create this post, click here.
Leave a comment
You can disable the adds below with Adblock Plus for your browser. Disqus is great for comments and feedback, but I had no idea it came with these awful ads.